K-Nearest Neighbor Algorithm on Python
Siapa bilang bahwa rumus pythagoras yang terkenal itu cuma konsep matematika yang diajarin dan ngga berguna didunia nyata, atau bahkan cuma sekedar masuk kuping kanan, muter-muter diotak sebentar, terus keluar lagi dari kuping kiri ???
Atau jangan-jangan malah kalian lupa sama sekali rumusnya ???
masih inget dengan persamaan berikut ini kan ???
persamaan diatas, bisa kita ilustrasikan sebagai berikut :
yaps, persamaan diatas digunakan untuk mencari nilai dari sisi miring apabila sisi tidur dan sisi berdiri dari segitiga siku-siku diketahui nilainya.
Lalu apa yang terjadi jika kita membuat sebuah model segitiga siku-siku kedalam bentuk koordinat kartesian kemudian kita asumsikan bahwa ujung yang dibentuk oleh garis cb dan garis ac merupakan sebuah koordinat titik ?? masih bingung ??? mari kita ilustrasikan
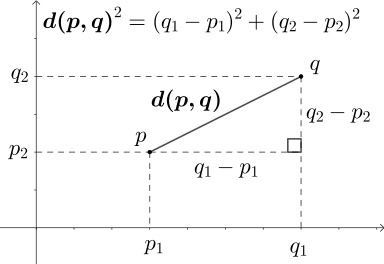
dari ilustrasi diatas, bahwa titik (p1,p2) dan titik (q1,q2) dan titik imajinasi lain yaitu titik (q1, p2) akan membentuk sebuah segitiga siku-siku imajinatif yang mana antara titik koordinat p dan q akan bisa dihitung nilainya atau dalam konteks ini bisa dicari jaraknya dengan persamaan matematika sebelumnya.
Lalu apa hubungannya dengan ilmu komputer ???
Pada Ilmu komputer, kita mengenal sebuah metode untuk membuat komputer bisa berfikir layaknya manusia, atau dalam konteks yang paling sederhana dapat membedakan sesuatu berdasarkan ciri-ciri tertentu, atau kita kenal sebagai Machine Learning.
Machine Learning
Pernah mendengar istilah machine learning atau dalam bahasa Indonesia bisa juga disebut pembelajaran mesin ? singkatnya Machine Learning atau pembelajaran mesin merupakan sebuah teknik atau juga solusi dalam mengembangkan sebuah sistem yang dapat mengambil informasi, menyimpulkan sesuatu, mengenali pola-pola tertentu secara mandiri dan juga independen tanpa arahan dari pengguna. Machine learning itu sendiri umumnya dikembangkan dari cabang ilmu yang lain terutama dari bidang matematika seperti statistika, probabilitas, vektor dan sebagainya sebagai landasan untuk mengambil kesimpulan.
Secara garis besar, ada dua model untuk menggambarkan machine learning, yaitu supervised dan unsupervised.
Unsupervised Vs supervised
Teknik ini merupakan penerapan Machine learning pada data yang tidak diketahui atribut kelasnya ataupun informasi mengenai data secara lengkap. Targetnya yaitu dapat mengambil pola-pola tertentu ataupun dapat mengelompokkan data secara otomatis berdasarkan hasil yang didapat dari pembelajaran mesin itu sendiri. Contohnya seperti clustering dengan algorima misalnya Kmeans. Sedangkan, supervised adalah teknik penerapan machine learning pada data yang telah diketahui karakteristiknya maupun yang diketahui atribut kelas atau kategorinya. Harapannya agar si mesin dapat mempelajari pola-pola dari data yang telah di ketahui informasinya ataupun kelasnya sehingga dapat mengambil kesimpulan baru atas pembelajaran yang telah dilakukan sebelumnya. Contoh dari pembelajaran model ini adalah K-NN atau K Nearest Neighbors.
KNN (K Nearest Neighbors)
Pada pembahasan kali ini, saya akan berfokus mengenai algoritma machine learning terutama model supervised yaitu K Nearest Neighbors dengan penerapannya pada bidang Text Mining atau penambangan teks. Text Mining merupakan proses pengambilan suatu informasi yang bernilai dan memiliki makna dari suatu kumpulan teks yang diperoleh dari penemuan pola-pola tertentu dan cenderung memiliki kesamaan yang khas(Yunindyo, 2020).
KNN atau K Nearest Neighbors merupakan sebuah algoritma supervised yang akan mengkategorikan data sesuai dengan kelas yang telah ditentukan dengan cara membentuk suatu hipotesa pada data yang diasumsikan sebagai titik pada ruang eucledian atau koordinat eucledian dan algoritma ini akan mengkasifikasikan data yang belum diketahui kategorinya berdasarkan jarak pada ruang vektor eucledian dengan dimensi sebesar K yang mengelilingi data yang telah diketahui kelas atau kategorinya. Dimana dengan asumsi data yang belum diketahui kategorinya dan memiliki jarak terpendek terhadap data tertentu yang telah diketahui kategorinya, maka data ini akan secara otomatis dihitung sebagai data yang memiliki kelas yang sama atau kategori yang sama.
mesti pada bingung baca bacaan ringan diatas ??? iyakan wkwkwk. oke Next …
Teori matematika KNN
Tak kenal maka tak sayang, sebelum lanjut kedalam praktik dengan menggunakan bahasa pemrograman python untuk membuat model KNN pada program, ada baiknya kita mengenal terlebih dahulu algorima knn ini. Yaitu dengan pendekatan matematika sebagaimana yang terlah di sebutkan dibagian sebelumnya. Bahwa data yang ada dianggap sebuah titik pada ruang vektor maka tentu akan ada rumus untuk menghitung jarak. Pada pengaplikasian metode KNN, banyak sekali rumus perhitungan jarak yang bisa digunakan untuk menghitung jarak vektor pada data latih. Misalnya Manhattan Distance, Minkowski Distance, Cossine Distance, atau dalam pembahasa ini berfokus pada rumus pertama dalam artikel ini yaitu eucledian distance atau yang kita kenal juga sebagai Pythagorean Distance. Dengan persamaan seperti berikut :
Karena data yang kita akan latih diangap sebuah titik dalam suatu vektor, maka kita dapat menghitung jarak antar titik-titik tersebut dan jarak terpendek kita ambil sebagai data yang memiliki similaritas yang serupa dengan rumus diatas.
Langkah Kerja
Pada pembahasan ini, contoh penerapan KNN dibatasi pada lingkup klasifikasi teks pendek berupa judul skripsi. Dimana nantinya judul ini akan dilatih dan diterapkan beberapa metode sekaligus untuk pembersihan data seperti stemming, stopword, penghitungan bobot dengan TF-IDF dan dengan tidak mengikutsertakan beberapa metode tambahan semisal post tag, ataupun metode-metode lain yang lebih spesifik semisal cakupan semantik bahasa dan sebagainya. Mengingat ruang lingkup dari teks ini mencakup ilmu kebahasaan yang advance ataupun ilmu semisal natural language processing lanjut.
Secara singkat, ada 3 bagian utama yang menjadi landasan pada tutorial kali ini yaitu
- Teks Analisis
- Transformasi Teks menjadi array vektor
- pengaplikasian Model KNN pada data
Prepared Tools
Untuk memulai tutorial ini, diharapkan para pembaca telah mengetahui basic pemrograman python dan telah menginstall pada perangkat kalian, virtual environtment. Langkah pertama kita buat terlebih dahulu virtual environtment.
python3 -m venv ./belajar-machine-learningkemudian dilanjutkan dengan mengaktifkan virtual environtment tersebut :
source ./belajar-machine-learning/bin/activatelalu menginstall package untuk kebutuhan coding, yaitu
pip install jupyterlab sklearn numpy pandas sastrawi seaborn nltksetelah menginstall package-package diatas, selanjutnya kita mengaktifkan jupyterlab dengan perintah berikut:
jupyterlabTeks Analisis
Tahapan dari bagian ini adalah kita akan mengekplorasi data dan melihat bagaimana bentuk dan struktur data baik dinilai secara kualitatif maupun kuantitatif, misalnya dari date range histori, bisa juga dilihat dari kategori data, dan sebagainya.
Untuk data sendiri, bisa di download pada laman github berikut :
- salin dan tempel pada berkas baru dengan ekstensi csv.
- semisal dumyData.csv
Selanjutnya, kita akan mengimport library yang dibutuhkan dengan perintah berikut :
# Import Libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Warnings
import warnings
warnings.filterwarnings('ignore')
# Text Preprocessing
import nltk
nltk.download("all")
nltk.download('/punkt')
import string
from nltk.tokenize import word_tokenizebuat baris baru kemudian load dataset kita kedalam variable:
finalExamTitles = pd.read_csv("../AppData/dumyData.csv", encoding = 'latin-1',delimiter=";",)
finalExamTitles.columns = ["Tahun Lulus","Judul","Kategori"]Pada potongan koding diatas, saya menyimpan data pada folder AppData, folder ini bisa disesuaikan dengan stuktur aplikasi teman-teman.
dilanjutkan dengan melihat banyaknya data yang kita punya :
print(f'Total Data : {finalExamTitles.shape[0]} items')dan akan menghasilkan hasil sebagai berikut:
Total Data : 372 itemsselanjutnya kita akan melihat struktur dari dataset yang kita punya dengan perintah berikut :
pd.options.display.width = 120
pd.options.display.max_colwidth = 80
pd.options.display.max_columns = 200
display(finalExamTitles.sample(n = 10))dengan hasil sebagai berikut :

langkah selanjutnya, kita akan melihat kelas atau kategori yang ada pada dataset yang kita miliki, dengan perintah berikut :
finalExamTitles["Kategori"].value_counts().plot(kind = 'barh')
plt.ylabel("Perbandingan Kategori")
plt.show()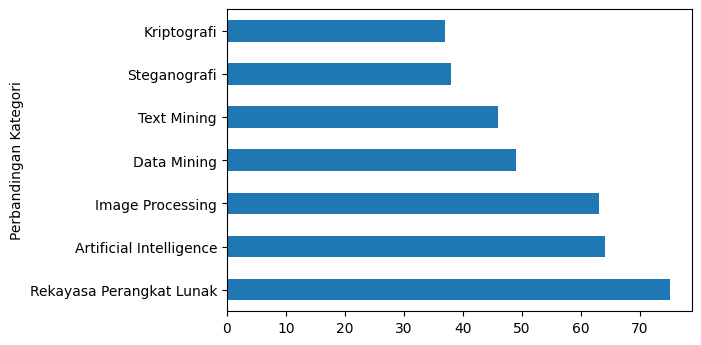
Selanjutnya kita akan melihat pembagian data berdasarkan tahunnya dengan perintah berikut :
finalExamTitles["Tahun Lulus"].value_counts().plot(kind = 'pie', explode = [0.1, 0.1,0.1], figsize = (6, 6), autopct = '%1.1f%%', shadow = True)
plt.ylabel("Percentage of Graduation Year")
plt.legend(["2019", "2018","2017"])
plt.show()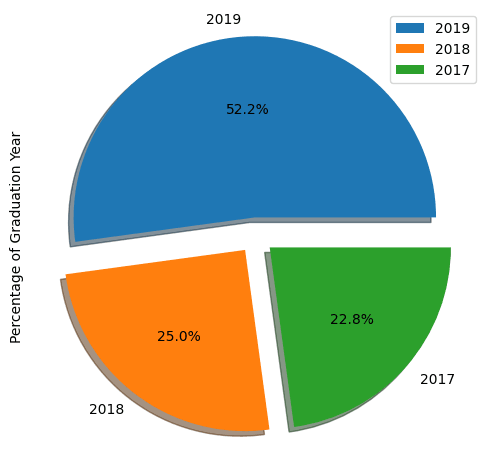
dari gambar diatas kita dapat mengetahui bahwa terdapat 3 partisi data berdasarkan tahun, yaitu 2017, 2018, dan 2019. Untuk selanjutnya kita bisa juga melihat topik-topik favorit dari masing-masing tahun dengan perintah berikut :
mostYearTopic=finalExamTitles[finalExamTitles["Tahun Lulus"]==2019]
most2019Topics=pd.value_counts(mostYearTopic['Kategori'].values, sort=True)
mostYearTopic["Kategori"].value_counts().plot(kind = 'pie', explode = [0.1, 0.1,0.1,0.1, 0.1,0.1,0.1], figsize = (6, 6), autopct = '%1.1f%%', shadow = True)
plt.legend(title="Most Topics on 2019",loc="center left",bbox_to_anchor=(1.5, 0, 0.5, 1))
plt.show()dan menghasilkan gambar berikut,
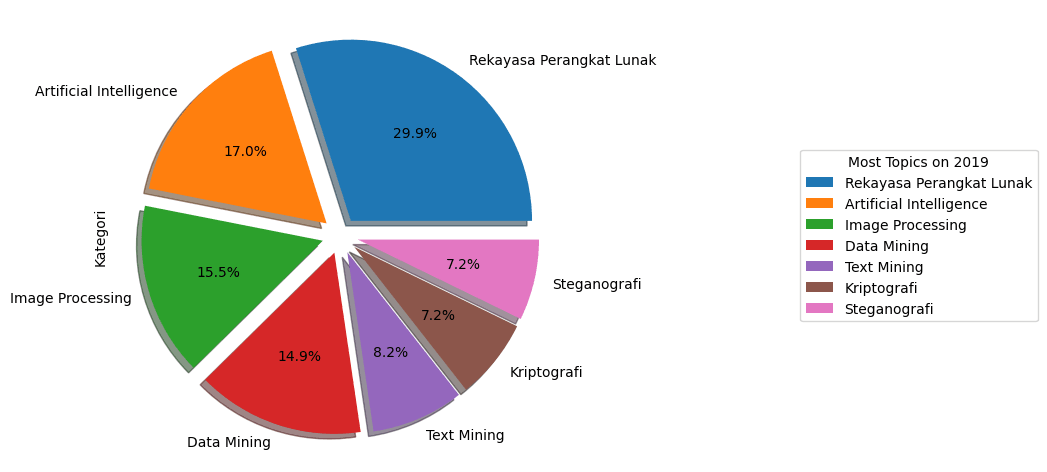
untuk tahun lainnya kita dapat menggantinya pada baris pertama dari potongan kode diatas,
mostYearTopic=finalExamTitles[finalExamTitles["Tahun Lulus"]==2019]disesuaikan dengan masing-masing tahun yang ada.
Text Processing
Dari langkah-langkah yang telah kita lakukan diatas, selanjutnya kita memasuki fase berikutnya yaitu Text Processing. Pada langkah ini kita akan membersihkan data kita yaitu judul Skripsi dengan beberapa langkah seperti Stemming, Stopword, dan melakukan perhitungan pembobotan kata atau weight term dengan metode TFIDF. Tujuan dari langkah ini adalah untuk membersihkan kata-kata yang tidak diperlukan serta merubah kata-kata tersebut menjadi vektor larik sehingga dapat dilakukan proses komputasi numerikal agar rumus jarak dapat diterapkan pada data yang kita miliki. Dalam proses ini pula, kita juga menggunakan beberapa library untuk membantu proses stemming dan stopword yaitu dengan sastrawi untuk stopword dan stemming bahasa Indonesia, dan juga NLTK stopword untuk bahasa Inggris jika ada kata yang berbahasa Inggris.
- Stopword
Sebuah metode yang digunakan untuk menghilangkan kata penghubung seperti ada, dan, untuk, dan sebagainya. Berikut contoh sebelum dan sesudah judul diimplementasi stopword.
| Sebelum stopword | sesudah stopword |
|---|---|
| APLIKASI PENGAMANAN PESAN DAN DATA MANIFES GAMBAR BERBASIS ANDROID DENGAN STEGANOGRAFI LSB DAN KRIPTOGRAFI AES | APLIKASI PENGAMANAN PESAN DATA MANIFES GAMBAR BERBASIS ANDROID STEGANOGRAFI LSB KRIPTOGRAFI AES |
| ---------------- | ---------------- |
| KLASIFIKASI KONTEN BERITA SECARA OTOMATIS PADA PROSES EDITORIAL HARIAN SUARA MERDEKA MENGGUNAKAN METODE NAIVE BAYES | KLASIFIKASI KONTEN BERITA OTOMATIS PROSES EDITORIAL HARIAN SUARA MERDEKA METODE NAIVE BAYES |
- Stemming
Stemming adalah proses untuk mengubah suatu kata berimbuhan menjadi kata dasarnya berikut contoh judul yang telah di stemming,
| No | Judul Teks |
|---|---|
| 1 | aplikasi aman pesan data manifes gambar basis android steganografi lsb kriptografi aes |
| 2 | klasifikasi konten berita otomatis proses editorial hari suara merdeka metode naive bayes |